RFC: Planning Copr → PULP RPM content movement
The Fedora Copr storage hosts (beginning of Y2024) approximately 33TB of data (RPM repositories and RPM files). The data is stored on a Fedora server, utilizing a rather complicated lvm+raid setup, all hosted on AWS EC2, typically hidden behind CDN (AWS CloudFront). Modifying this setup and further maintenance is non-trivial (adding new arrays of disks into LVM, migrating the box to new Fedora releases, etc).
We’d like to use something that auto-scales long-term, either something like Amazon EFS (seems more expensive compared to our current setup) or S3 (implies a significant rewrite of Copr code).
Also, things used to be relatively trivial years ago. With the current data payload though, even some of our logic needs to be updated (both for convenience and performance).
Wait, we are not the first team hosting RPMs, right? There’s PULP! Why not delegate the heavy-lifting to the project designed for RPM content hosting (actually having the S3 support)? Sure, the switch is not going to be trivial. In this post, I’d like to at least propose the basic “stages” for the hostname migration (how users consume the storage).
The old state
The results are served by lighttpd on the Copr Backend box, in the
non-cached results directory, and cached by
CloudFronts (fp.o = fedoraproject.org, fic.o =
fedorainfracloud.org).

All users consume content through CDN,
download.copr.fedorainfracloud.org.
The migration time
We’ll start with a new hostname related to the PULP server. We are not
sure whether we’ll use the PULP built-in HA,
CloudFront, or both. Initially, we’ll begin moving a small set of
projects, and the copr-be.cloud.fp.o box will have to start redirecting
(some) requests to them to, e.g., pulp.copr.fp.o. You may wonder if
this “redirection” is supported by DNF5, DNF, and YUM customers — it is
(tested even on CentOS 6).
Migrated Copr projects will provide updated .repo files (like
this), pointing to the PULP hostname. So, when users
start consuming project content, e.g., with dnf copr enable, their
machines will not have to follow the redirects!
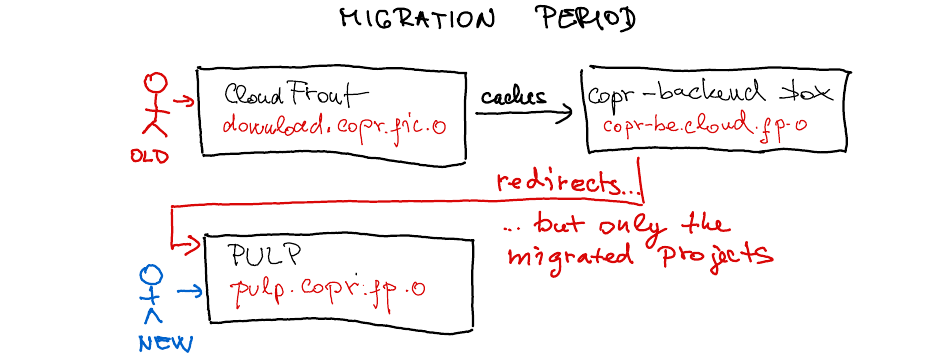
Once done
The download.corp.fedorainfracloud.org no longer points to the
CloudFront cache but directly to the PULP host. This change will be
necessary for some indefinite amount of time to remain compatible with the
old .repo file installations.
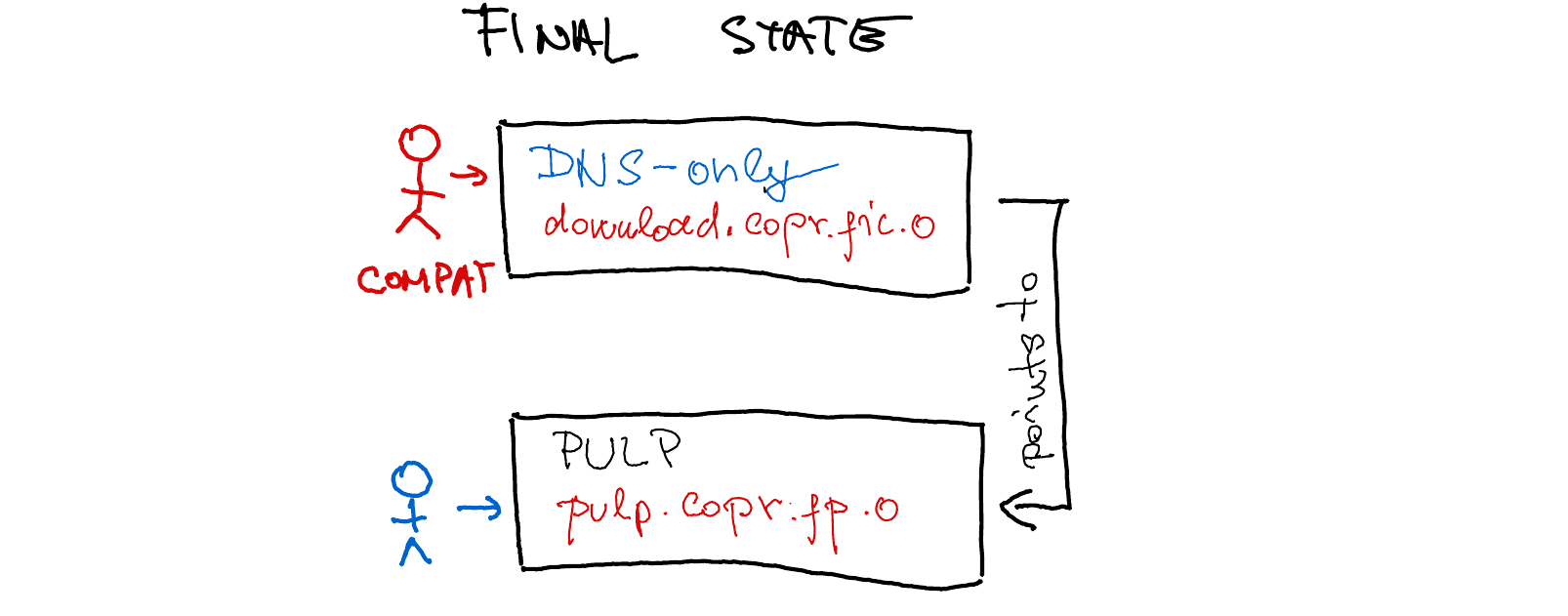
Bad idea?
The primary motivation for this flow is to ensure the smoothest possible experience throughout all phases (repositories available all the time).
Please let us know if you have any concerns or questions. Otherwise, just stay tuned for further updates!