Empower your writing with Ramalama
Have you ever asked ChatGPT or other online AI services to review and correct your emails or posts for you? Have you ever pondered over what the service or company, such as OpenAI, does with the text you provide them “for free”? What are the potential risks of sharing private content, possibly leading to copyright headaches?
I am going to demonstrate how I use Ramalama and local models instead of ChatGPT for English corrections, on a moderately powerful laptop. The latest container-based tooling surrounding the Ramalama project makes running Language Models (LLMs) on Fedora effortless and free of those risks.
Installation and starting
Ramalama is packaged for Fedora! Just go with:
dnf install -y ramalama
It is a fairly swift action, I assure you. Do not be misled though. You will need to download gigabytes of data later on, during the Ramalama runtime :-)
I take privacy seriously, the more isolation the better. Even though Ramalama claims it isolates the model I’d like to isolate Ramalama itself. Therefore, I create a new user called “ramalama” with the command:
useradd ramalama && sudo su - ramalama
This satisfies me, as I trust the Ramalama/Podman team’s that they do not escalate privileges (at least I don’t see any setuid bits, etc.).
Experimenting with models
ramalama run: error: the following arguments are required: MODEL
The tool does a lot for you, but you still need to research which model is most likely the one you require. I haven’t done an extensive research myself, but I’ve heard rumors that LLama3 or Mistral are relatively good options for English on laptops. Lemme try:
$ ramalama run llama3
Downloading ollama://llama3:latest ...
Trying to pull ollama://llama3:latest ...
99% |█████████████████████████████████████████████████████████████████████████ | 4.33 GB/ 4.34 GB 128.84 MB/s
Getting image source signatures
Copying blob 97024d81bb02 done |_
Copying blob 97971704aef2 done |_
Copying blob 2b2bdebbc339 done |_
Copying config d13a3de051 done |_
Writing manifest to image destination
🦭 > Hello, who is there?
Hello! I'm an AI, not a human, so I'm not "there" in the classical sense. I exist solely as a digital entity,
designed to understand and respond to natural language inputs. I'm here to help answer your questions, provide
information, and chat with you about various topics. What's on your mind?
Be prepared for that large download (6GB in my case, not just the 4.3GB model; I’m including the Ramalama Podman image as well).
The command-line sucks here, server helps
Very early on, you’ll find that the command-line prompt doesn’t make it easy for
you to type new lines; therefore, asking the model for help with composing
multi-line emails isn’t straightforward. Yes, you can use Python’s multi\nline
strings\nlike this one, but for this you’ll at least need a conversion tool.
I want to have a similar UI with the ChatGPT, and it is possible!
$ ramalama serve llama3
OpenAI RESTAPI: http://localhost:8080
... starting ...
Getting this in web browser:
But after a while:
...
srv log_server_r: request: POST /v1/chat/completions 192.168.0.4 500
srv log_server_r: request: GET / 192.168.0.4 200
srv log_server_r: request: GET /props 192.168.0.4 200
Admittedly, that’s just too much. I don’t need a full prompt; I’d still prefer
a simple command-line interface that would let me provide multiline strings and
respond with the model’s answer. Nah, we need to package python-openai into
Fedora (but it is not yet there).
Performance concerns
Both llama3 and Mistral respond surprisingly quickly. The reply starts immediately, and they print approximately 30 tokens per second. Contrastingly, Deepseek takes much longer to respond, approximately a minute, but the token rate is roughly equivalent.
I was surprised to find that while the GPU was fully utilized, NVTOP did not report any additional GPU memory consumption (before, during or after model provided the answer). Does anyone have any ideas as to why this might be the case?
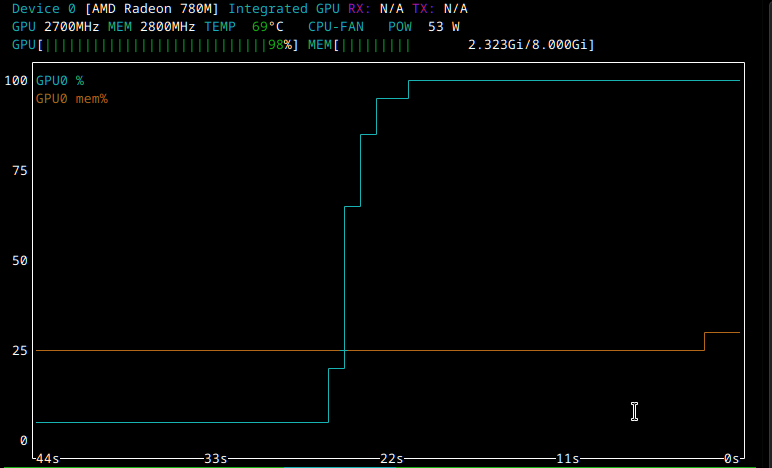
Summary
The mentioned models perform exceptionally well for my use-case. My interactions with the model look like:
fix english:
the multi-line text
that I want to correct
and the outputs are noticeably superior to the inputs :-).
More experimentation is possible with different models, temperature settings, RAG, and more. Refer to ramalama run –help for details.
However, I have been encountering some hardware issues with my Radeon 780M. If I run my laptop for an extended period, starting the prompt with a lengthy question can trigger a black screen situation, leaving no other interactions possible (reboot needed). If you have any suggestions on how to debug these issues, please let me know.